MisterCoding
1.2k Views
"TikTok, platform video yang meroket popularitasnya, menghadapi masalah serius pada salah satu layanan inti mereka. Layanan pembayaran yang andal, yang dibangun menggunakan bahasa pemrograman Go, mulai menunjukkan tanda-tanda ketahanan saat beban pengguna terus meningkat. Khususnya pada fitur TikTok LIVE, di mana interaksi real-time menjadi sangat krusial, layanan pembayaran ini menjadi titik bottleneck."
Dalam dunia sistem bertingkat tinggi, kesuksesan sering kali membawa tantangannya sendiri. Ini dialami langsung oleh Wu Xiaoyun, seorang karyawan TikTok yang berbagi pengalamannya menghadapi situasi menantang selama magangnya di perusahaan media sosial raksasa tersebut.
TikTok, platform video yang meroket popularitasnya, menghadapi masalah serius pada salah satu layanan inti mereka. Layanan pembayaran yang andal, yang dibangun menggunakan bahasa pemrograman Go, mulai menunjukkan tanda-tanda ketahanan saat beban pengguna terus meningkat. Khususnya pada fitur TikTok LIVE, di mana interaksi real-time menjadi sangat krusial, layanan pembayaran ini menjadi titik bottleneck.
"Ketika basis pengguna TikTok LIVE terus bertambah, beban CPU pada layanan ini meningkat tanpa henti, dan kami dihadapkan pada alarm stabilitas yang terus-menerus dari layanan yang mencapai ambang batas CPU," ungkap Wu dalam artikel yang ditulisnya.
Tantangan ini menciptakan dilema klasik dalam rekayasa perangkat lunak: bagaimana cara memeras performa lebih banyak dari sistem kritis tanpa mengorbankan stabilitas atau menghabiskan biaya besar?
Alih-alih melakukan penulisan ulang menyeluruh yang berisiko tinggi, tim Wu Xiaoyun memilih pendekatan yang lebih hati-hati dan terukur. Mereka mengidentifikasi titik-titik API yang paling banyak mengkonsumsi sumber daya CPU dan memutuskan untuk menulis ulang hanya bagian-bagian tersebut menggunakan Rust.
"Kami memutuskan untuk bereksperimen dengan Rust, bahasa yang menawarkan performa mendekati bare-metal tanpa mengorbankan keamanan memori," jelas Wu. "Rencananya adalah menulis ulang hanya segelintir endpoint API yang terikat oleh CPU dalam Rust dan membiarkan bagian lain dari layanan Go tidak tersentuh."
Pendekatan poliglot ini, terinspirasi oleh studi kasus implementasi sukses dari tim lain, memungkinkan mereka untuk menerapkan alat khusus tepat di tempat yang paling dibutuhkan.
Sebelum memikirkan performa, prioritas utama tim adalah memastikan kebenaran hasil. Layanan yang lebih cepat dan lebih murah akan menjadi sia-sia jika mengembalikan data yang salah.
Untuk memvalidasi implementasi Rust baru, tim meng-deploy layanan tersebut dalam "shadow mode". Selama berminggu-minggu, layanan baru menerima salinan lalu lintas produksi langsung, berjalan paralel dengan layanan Go asli. Mereka menggunakan pipeline validasi yang kuat yang dengan cermat membandingkan respons dari layanan Rust dengan respons dari layanan Go untuk setiap permintaan tunggal.
"Baru setelah mengkonfirmasi 100% konsistensi data, kami mendapatkan kepercayaan diri untuk melanjutkan," papar Wu.
Hasil dari uji tekanan bahkan melebihi harapan mereka. Layanan Rust menunjukkan performa yang jauh lebih unggul secara keseluruhan.
Untuk endpoint paling kritis, layanan Go warisan mulai berguncang sekitar 85.000 QPS (Queries Per Second). Sementara itu, layanan Rust baru, berjalan pada perangkat keras yang persis sama, dengan mudah menangani lebih dari 150.000 QPS—peningkatan sekitar 1,8x. Untuk endpoint kunci lainnya, perbedaannya bahkan lebih mencolok: layanan Go mencapai puncaknya pada 105.000 QPS, sementara layanan Rust mencapai puncak pada 210.000 QPS—peningkatan performa bersih 2x.
Lonjakan dari peningkatan ~1,8x menjadi peningkatan penuh 2,0x bukanlah kebetulan; itu adalah hasil dari analisis performa yang mendalam, dengan studi teliti terhadap flame graphs, implementasi struktur data copy-on-write, dan minimisasi operasi memcpy di mana pun memungkinkan.
Berikut adalah perbandingan yang disederhanakan pada beban tinggi 80.000 QPS, masing-masing layanan dengan klaster yang memiliki 40 core vCPU dan 80 GB RAM:
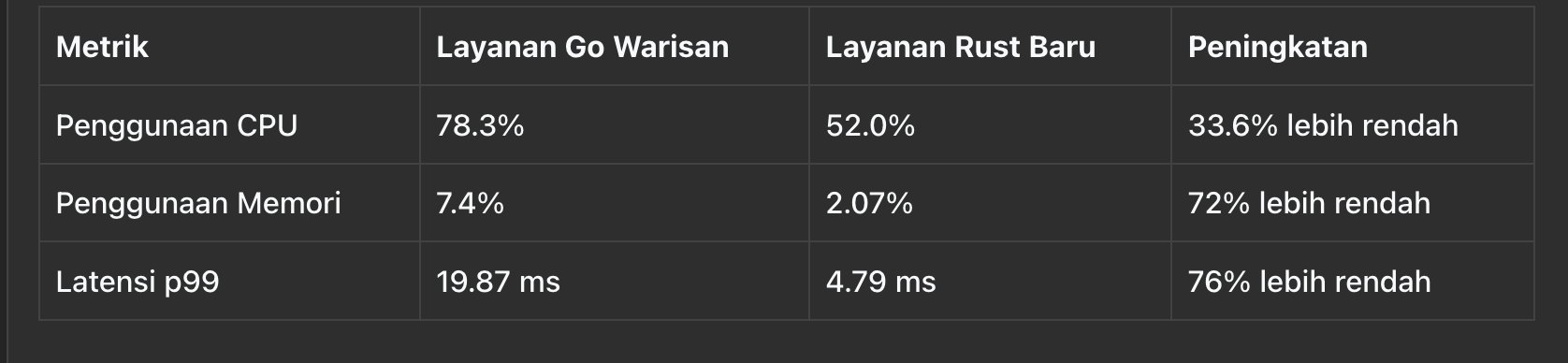
Peningkatan performa ini secara langsung diterjemahkan menjadi penghematan biaya yang massive. Dengan menangani dua kali lipat lalu lintas per mesin, mereka dapat secara drastis mengurangi jumlah core komputasi yang diperlukan.
"Analisis akhir kami menunjukkan pengurangan lebih dari 400 core vCPU, yang mengarah pada proyeksi penghematan biaya infrastruktur tahunan lebih dari $300.000," ungkap Wu.
Ia menambahkan bahwa banyak pembaca yang mungkin berpikir penghematan ini terlihat kecil mengingat skala TikTok, namun perlu dipahami bahwa penghematan $300.000 ini berasal dari penulisan ulang parsial dari hanya satu mikrojian dalam platform pembayaran TikTok LIVE. Sebanyak 99% layanan di platform pembayaran masih ditulis dalam Go.
Proyek ini mengukuhkan prinsip rekayasa yang krusial: gunakan alat yang tepat untuk pekerjaan yang tepat. "Ini bukan cerita tentang 'Rust lebih baik dari Go'," jelas Wu. "Ini adalah cerita tentang kematangan rekayasa dan optimasi strategis."
Justru sebaliknya, proyek ini memberinya pemahaman yang lebih mendalam tentang Golang. "Produktivitas pengembang yang luar biasa dan performa yang seimbang dari Go menjadikannya pilihan ideal untuk 95% layanan kami," ujarnya. "Ini memungkinkan kami untuk membangun, mengirimkan, dan memelihara fitur dengan kecepatan cepat. Kesuksesan kami dengan Go adalah yang memungkinkan kami memiliki layanan yang sangat populer sehingga membutuhkan tingkat optimasi ini pada tempat pertama."
Dengan mengidentifikasi bottleneck performa kritis dan menerapkan solusi yang ditargetkan dan teruji dengan baik, tim Wu berhasil menggandakan kapasitas layanan inti, secara signifikan meningkatkan latensinya, dan mengurangi biaya operasional secara drastis. Meskipun proyek ini sebagian besar merupakan upaya individu, keberhasilannya tidak akan mungkin terjadi tanpa bimbingan berharga dari mentornya dan dukungan rekan kerjanya.
"Perjalanan ini adalah pengingat kuat bahwa terkadang, kemenangan terbesar tidak datang dari menulis ulang semuanya, tetapi dari membuat perubahan cerdas dan strategis tepat di tempat yang paling penting," tutup Wu.
Sumber Resmi:
Share this article:

Anthropic Akuisisi Bun: Integrasi Strategis Runtime JavaScript dengan AI Coding
Apa Itu GraphQL? Kapan Menggunakannya dan Kelebihannya untuk Aplikasi

Human in the Loop (HITL) pada Agent AI: Ketika Manusia dan Mesin Berkolaborasi Secara Cerdas

Dragonfly: Solusi In-Memory Data Store Modern yang Siap Menggantikan Redis